In the past one and a half months, I have been working on consensus protocol, especially view change protocol. This is one of the core parts in any blockchain project, from which we can tell whether a blockchain is permissioned or permissionless and how decentralized it is. The consensus code is here: harmony/consensus. Our mainnet is launched with a total of nodes, it contains shards, with nodes per shard. It is running smoothly. In our previous tests, we observed view change (i.e. leader change) happened in some shards due to bad network condition. I also manually triggered view change by killing the leader node as well as other kinds of attack factors. The view change happened after the attack and the network is still keep going as expected, yeah! In the following, I will first explain the basic concepts of byzantine fault tolerant, then how do we improve it to handle large number of nodes in practice, and finally I will explain overall code structure and some implementation details.
What is Byzantine Fault Tolerance
A distributed system consists of multiple nodes, where assume each node is an independent server and they are communicating with each other by sending messages over the network and perform some tasks according to the protocol they conform. There are many types of faults, but they can basically be classified into two large categories. The first kind of faults are node crash, network down, packet loss etc, where the node had no malicious intention, they are Non-Byzantine faults. The second kind of faults are that a node can be malicious, it can act arbitrarily and not follow the rules of the protocol. e.g. in blockchain world, a validator can delay or refuse to relay the messages in the network. The leader can propose invalid block. A node can send different messages to different peers. Even worse, the malicious nodes can collaborate with each other. They are called Byzantine faults.
With these two kinds of faults in mind, there are two properties we want the system to maintain: consistency and liveness. In blockchain terminology, consistency means the honest node must commit the same block for any given block number/height; liveness means the chain height must keep growing without stuck.
In a permissioned network condition, where we only have first kind of faults, this is easier to achieve. For example, we can pick one powerful node as leader and all the other nodes will just listen to what the leader broadcast and trust any block the leader proposes. Even in this case, we need to take care of the first kind of faults, especially when it happens to the leader.
For a fully decentralized network, we cannot trust any single node and assume the second kind of faults can happen in any node. There is only one fundamental assumption, that is a malicious node cannot forge the signatures other nodes signed. This is guaranteed by cryptography theory, where the difficulty of forging a signature is so high that no computer today can break in any practical time. Things might change when the quantum computer is ready. But at that time, we will use quantum-resistant cryptographic algorithm instead.
A Byzantine Fault Tolerant protocol is a protocol that can guarantee the consistency and liveness of the distributed system even there are malicious nodes in the system. All such protocol have basic assumption that the number of malicious node is less than some threshold. This is easy to understand, if there are over malicious nodes, then the network is fully controlled by the malicious nodes. In the case of prove of work (PoW) in bitcoin, the requirement is less than of nodes (in the computation power sense) are malicious. However, the selfish mining makes the basic assumption lower to . i.e. the system of PoW will be safe only if less than of nodes (in the sense of computation power) are malicious. There are a lot of research on Byzantine Fault Tolerance protocol in traditional distributed system area. It is proven that the malicious nodes should be less than in the classical paper of lamport. Later on, the famous practical byzantine fault tolerance paper PBFT make such system practical in use.
There are still two remaining issues. First, such a system is permissioned, which not allow arbitrary nodes leave and join. Second, it is not scalable to more than hundreds of nodes. The first issue is due to the Sibil attack, where a malicious user can easily fake a lot of fake identities and take over the majority of the network. It is first solved in Satoshi Nakamoto’s bitcoin whitepaper, where the economic effect is taken into consideration. After proof of work (PoW), there are a bunch of new designs such as proof of stake (PoS), proof of authority (PoA) etc. Instead of counting the number of nodes, we counting number of voting power. In PoS, the voting power of a node is proportional to its staking amount. The second issue is solved by aggregated signatures using BLS signature scheme which is explained in FBFT section.
Practical Byzantine Fault Tolerance
For protocols like Raft and Paxos, they are used to deal with first kind of system faults. Practical Byzantine Fault Tolerance (PBFT) is one of the first Byzantine fault tolerance protocols used in the real world to deal with both first and second kinds of faults. We will always assume there are nodes with at most malicious nodes, where . There are two modes in the PBFT, the normal consensus (normal in short) mode and the view change mode. The normal mode looks like this (in blockchain, the client request and reply can be ignored):
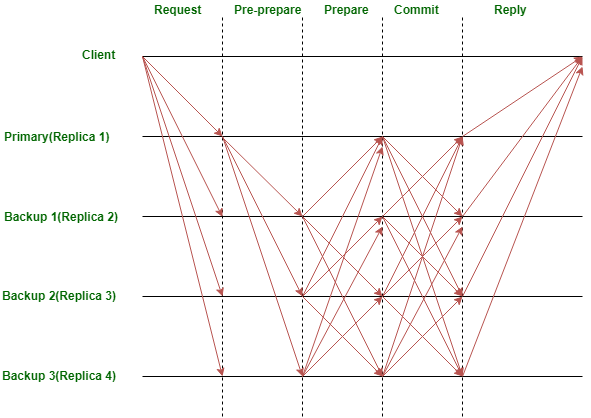
In one view (one view is a similar concept of one round), there are steps/phases: pre-prepare (announce), prepare and commit.
- In pre-prepare(announce) phase, the leader will broadcast announce message (e.g. the proposal block) to other nodes (called validators). When a validator receives announce message, it enters prepare phase.
- In prepare phase, after a validator receives announce message, it will broadcast prepare message (e.g. signature on blockhash) to every node. When a validator (including the leader) receives enough (i.e. ) prepare messages, it will enter commit phase.
- In commit phase, a validator (including the leader) will send commit message (e.g. signature on ). When a validator receives enough () commit messages. It can safely commit the block. This ends one round of normal consensus process.
Notice that there are some differences between general PBFT and blockchain PBFT. The major difference is that the blockchain is “synchronized” between two blocks, i.e. we cannot proceed to commit block before commit . In the traditional PBFT, we can commit client request before request . The PBFT will guarantee the consistency across all the nodes. In this sense, the blockchain makes consensus process simpler. To be precise, there is a process in PBFT called checkpoint process, a checkpoint is a certificate that all the information with sequence number (in blockchain, it is the block number) less or equal than checkpoint’s sequence number are finalized. In blockchain, each committed block is finalized and can be viewed as a checkpoint.
When a validator cannot commit a new block before consensus timeout (), the validators will start view change (), the new leader is uniquely determined in a predetermined way. If the view change cannot finish before timeout (), the validator will propose another view change (, with view change timeout increases to ).
There are steps/phases in view change mode:
- A validator starts view change by sending view change message containing prepare messages to new leader. If it doesn’t receive enough prepare messages, it just send view change message without any prepare message to the new leader.
- The new leader collects enough () view change messages and broadcast new view message containing view change messages it receives. Then the new leader switches to normal consensus mode. A validator switches to normal mode when it receives new view message from the new leader, at the same time, it stops the view change timer and start consensus timer. If the validator doesn’t receive new view message before view change timeout, it will increase viewID by one and start another view change.
View change guarantees the liveness of the network. During the view change process, we need to make sure the block committed is consistency across view change as well. Simply speaking, the receiving of prepare messages only ensure the consistency in the same view. The receiving of commit messages ensure the consistency across different views. When a node receives commit messages, it can safely commit the block into the blockchain. The PBFT protocol ensures the same block will be committed by any honest nodes even in the case of view change.
Consistency and Liveness
The key concept in PBFT is the quorum. A quorum is any subset with at least nodes. Since there are total of nodes, any two quorums will intersect at least nodes. Based on the assumption that there are at most malicious nodes, there will be at least one honest node in the intersection of two quorums. This is the reason why we need a quorum to take any action.
Consistency in one view: Suppose a node received prepare message, these nodes form a quorum. Notice any two quorums will have at least one honest node in common, it means any two such quorums cannot contain different block hashes in their prepare messages, otherwise the honest node in common admits two different blocks of the same height which contradicts the fact it’s honest.
Consistency across different views: Suppose a node received commit messages, these nodes form a quorum, denote it as . When an honest node starts view change, it will send it’s prepared message (contains prepare messages) to new leader. The new leader needs to collect view change messages (denote as quorum ) in order to send new view message. Again and contains at least one honest node. This node contains prepare messages because it received enough prepare messages before it sent out its commit message. This ensures the same block will be committed by honest nodes across different views.
Liveness: Each node has a timer for normal consensus process (with timeout) and a timer for view change process (with timeout, where is how many view changes happened before a validator can switch back to normal mode). When the timer timeout, the node will start view change by increase view by one. In the case of consecutive leaders fail to send correct new view messages, the timeout period of view change timer will be increased to avoid to frequently view changes and to make sure eventually enough honest nodes will have same viewID with honest new leader.
Fast Byzantine Fault Tolerance
BLS signature scheme
Here we give a very brief and mathematical introduction to Boneh–Lynn–Shacham (BLS) signature scheme which is main distinguisher between FBFT and PBFT. The BLS signature is based on elliptic curve pairing. Let to be the elliptic curve over finite field where is a large prime number. We pick a basic reference point on this curve. The private BLS key is a random number sampled from and the public key is which is a point on . Given a message , the signature is calculated as which is a point on , where is a hash function to .
A bilinear map on two elliptic curves and is a pairing if
Now we can see how the signatures are aggregated and verified by aggregated public key.
Notice the aggregated signature is just one normal signature which is a point on elliptic curve, the aggregated public key is normal public key which is also a point on elliptic curve. This reduces the signatures into just aggregated signature which is critical to reduce network traffic in consensus protocol.
normal mode
In traditional PBFT, the total message size a node sends or receives in each round of consensus is . This is because in prepare and commit phases, every node needs collect signatures and broadcast them to every node (i.e. nodes) in network. By using the BLS signature scheme, we aggregate the signatures into one signature, this way the message size in prepare and commit phases are , which reduces the total size from to in one round. To benefit from BLS scheme, every validator will send prepare and commit message to leader only and the leader is responsible to collect enought signatures and aggregated them into one aggregated signature, after that the leader sends the prepared/committed message in prepare/commit phase respectively. From the leader’s perspective, the three phases are synchronized, but from validators’ point of view, they can still receive messsages out of order, e.g. a validator can receive prepared message before announce message, however in this case, its prepare signature will not be include in the prepared message.
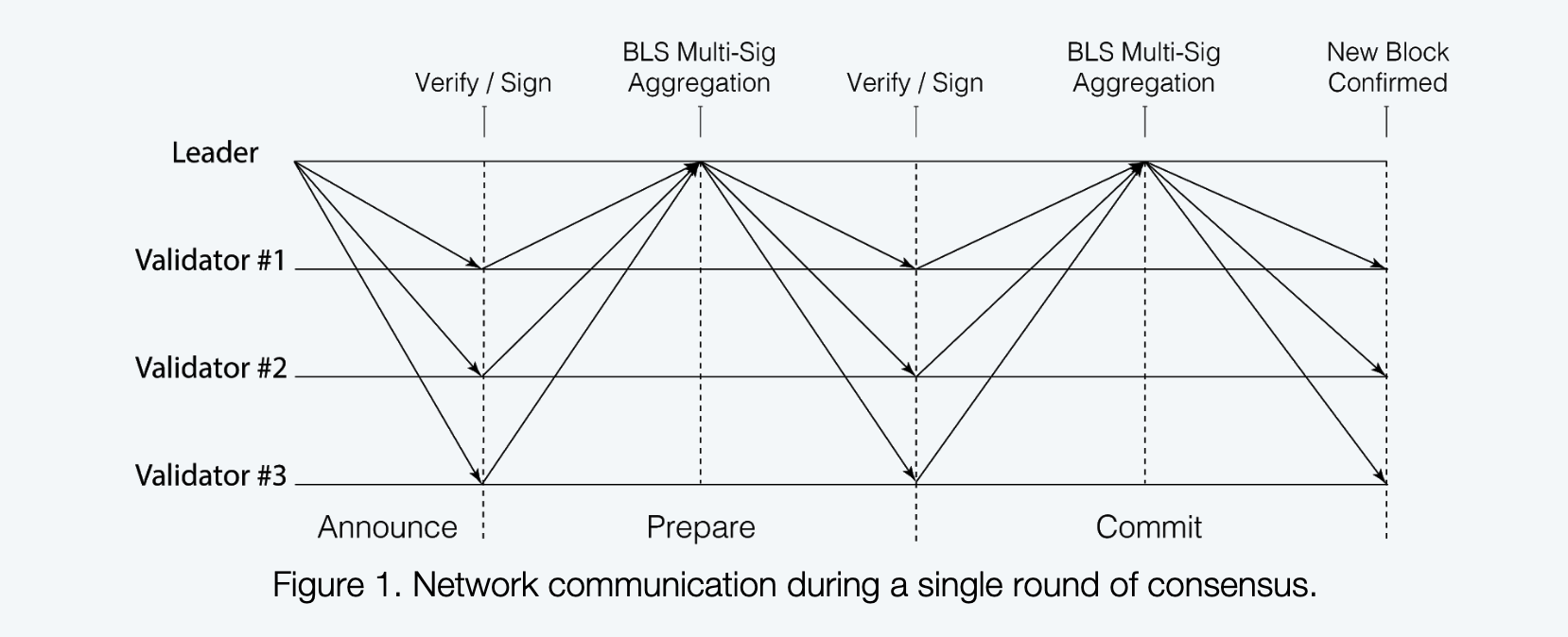
There are three phases in the normal mode:
- In announce phase, the leader will broadcast announce message (e.g. the proposal block) to validators. When a validator receives announce message, it enters prepare phase
- In prepare phase, the validator sends prepare message (e.g. signature on blockhash) to leader. When leader receives enough (i.e. ) prepare messages, it aggregates signatures of prepare messages received from validators and sends out prepared message contains aggregated prepare signatures. Then the leader enters commit phase. A validator enters commit phase when it receives prepared message from the leader.
- In commit phase, the validator sends commit message (e.g. signature on ) to leader. When the leader receives enough (i.e. ) commit messages, it aggregates signatures of commit messages received from validators and sends out committed message contains aggregated commit signatures. Then the leader finishes one view/round. A validator finishes one view/round after it receives committed message. When the leader or validator finishes one round, it will restart the consensus timer.
In step $3$ commit phase, the validator sends commit message with signature on blockNumber and blockHash. This is convenient for the node to quickly determine whether it is out of sync without tricked by the malicious leader. How the consensus process interacts with state syncing is explained in the state syncing mode section.
leader election
There are two causes for validators to start view change process. One cause is when a validator detects the leader proposed two different announce messages in one view, it will immediately start view change. The other cause is a validator doesn’t make any progress after timeout. There are two kinds of timeouts: timeout in normal consensus mode and timeout in view change mode.
In our blockchain, we have the concept of epoch. Each epoch contains $X$ blocks (e.g. $X=1000$). In the beginning of each epoch, the committee members are determined by who has staked for this epoch in the beaconchain. The order of the committee members is uniquely determined by the VDF randomness of this epoch. During one epoch, the committee will always stay the same. Suppose the order list is $[v_0,v_1,\cdots,v_n]$. Then in the beginning of epoch, the leader is $v_0$. If view change happens, the next leader is $v_1$, and so on. Here we assume each validator has equal voting power.
view change mode
The view change process is as follows:
- When the consensus timer timeouts, a node starts view change by sending view change message including viewID and prepared message (containing aggregated signatures) to new leader. If it doesn’t receive prepared message, it just sends view change message including signature on viewID but without prepared message.
- When the new leader receives enough () view change messages, it aggregates signatures of viewID and just pick one prepared message from view change messages. It broadcasts new view message including aggregated signatures as well as the picked prepared message. Then the new leader switches to normal consensus mode. A validator switches to normal consensus node when it receives new view message from the new leader, at the same time, it stops the view change timer and start the consensus timer. If the validator doesn’t receive new view message before view change timeout, it will increase viewID by one and start another view change.
The second step requires each validator to send signature on viewID, the purpose is to reduce the size of new view message from to when the previous leader is malicious. To be precise, the previous leader can send different aggregated signatures to different validators in prepared phase. As long as the aggregated signature is valid, the validator will accept it and propose it when view change happens. In this scenario, the size of new view message is , because the new leader has to prove the receiving of enough valid view change messages. With everyone signed on viewID, it’s possible for new leader to aggregate the signatures to reduce new view message size to again. Only this way, we can scale up the number of nodes in the network in the case of view change.
state syncing mode
We allow a node to join and leave freely in blockchain. When a new node joins consensus, it has to do state syncing before it can validate consensus messages. Also, there are situations when a node gets stuck in view change mode. e.g. When a validator has slow network connection, it may not be able to make any progress before timeout. In this case, it will start view change. However, there is no way it can escape from view change mode because all the other nodes are moving forward and the view change will fail. In this case, this node needs to do state syncing to catch up.
The basic process is simple. When a node detects it’s out of sync by comparing its current block height with the latest block height in committed message, it will switch to state syncing mode and start doing state syncing. After it finishes state syncing, it switches to normal mode.
In order to join the consensus after state syncing finished, a node needs to know who is the current leader and what is the current viewID. One solution is to blindly accept whatever the leader and viewID from the consensus message. This approach gives the malicious leader the chance to send a large viewID along the consensus message to make every validator starts doing consensus. A better way is only accept the leader and viewID information when the node receives the committed message from the network. In this case, the malicious leader cannot trick the new node. But it slows down the process of new node joining consensus because it cannot verify announce and prepared messages until leader and viewID updated. The approach we choose is to add leader and viewID information into the block header. When a node finished state syncing, it can read the information from the latest block header. If during the state syncing, the view change happened, the information from the latest block is outdated. In this case, a new node can still update the leader and viewID information when it receives committed message.
State Transition
The following drawing is the state transition graph of a validator. The state transition graph of a leader is simpler and omitted here.
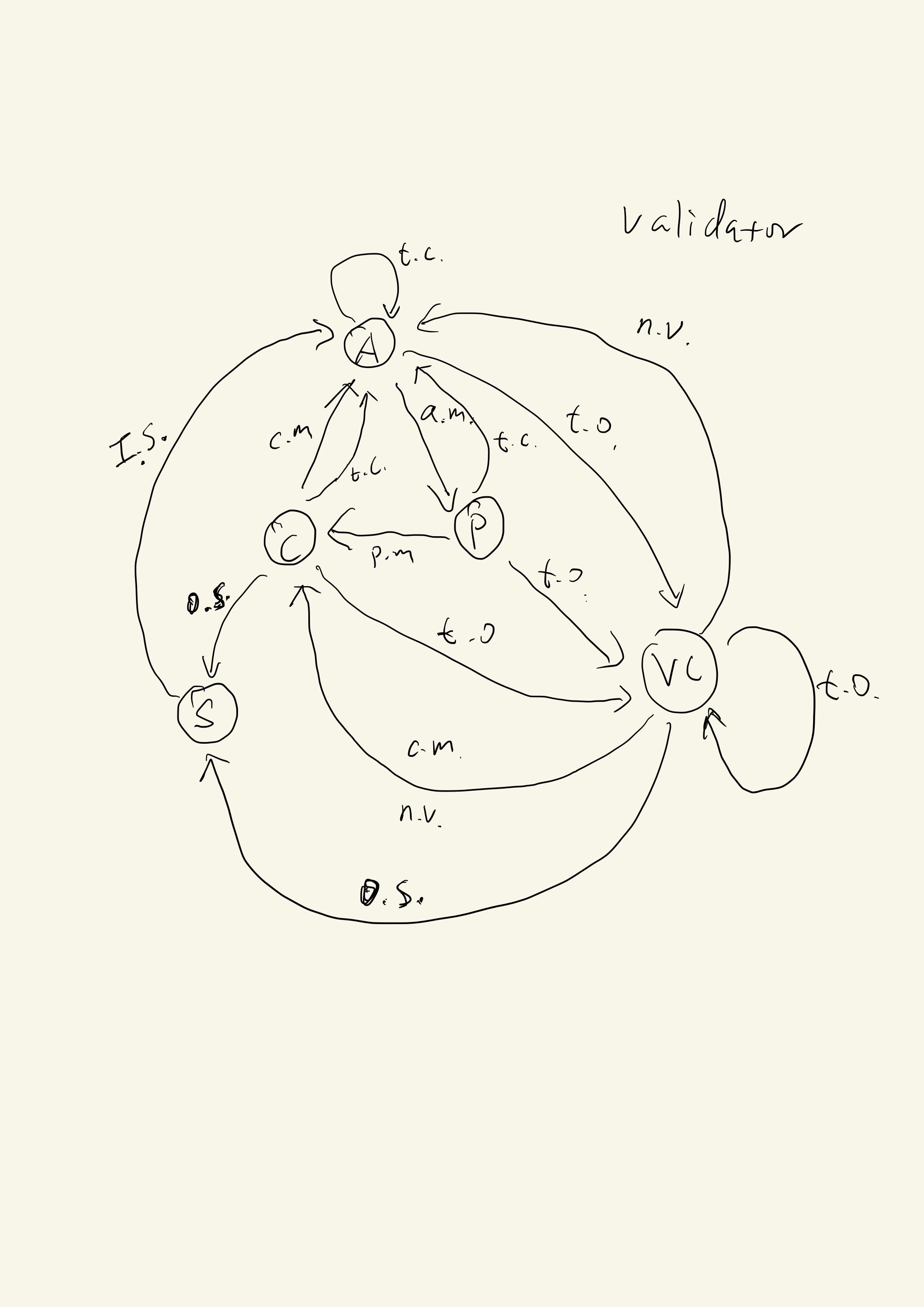
There are modes: normal modes (A: Announce, P: Prepare, C: Commit), view change mode (VC) and state syncing mode (S).
The transitions between modes are triggered by different conditions such as receives a specific type of message or meet some conditions like timeout.
Condition list: a.m (announce message), p.m (prepared message), c.m (committed message), t.c (try catchup success), t.o (timeout), n.v (new view message), i.s (in sync), o.s (out of sync).
Comparison with Tendermint and HotStuff
We compare FBFT with Tendermint and HotStuff (TODO)